

Engineering
AI agents can analyze code, understand natural language queries, and generate recommendations. But making them reliable enough for production use requires more than model capabilities. The gap between "works in a demo" and "works in production" is infrastructure: orchestration, caching, security, observability, and deterministic execution guarantees.
This post describes TaskOrchestrator, the orchestration system we built for Frugal Code. We'll walk through the specific technical challenges of production AI systems and how TaskOrchestrator addresses each: breaking complex problems into manageable tasks, managing state and caching, ensuring security, and providing execution visibility.
Architecture Overview
TaskOrchestrator treats AI agents as components within a larger workflow system rather than as standalone applications. The AI agent executes within individual tasks, while the orchestrator manages task dependencies, caching, parallelization, and execution environments.
The following sections detail the key subsystems that enable reliable AI agent execution in production.
Task Decomposition and DAG Orchestration
Complex analysis tasks present a significant challenge for AI agents when tackled as monolithic problems. A query like "analyze S3 cost drivers" produces unreliable results when given to a single agent. We address this through systematic decomposition into smaller, well-defined tasks with explicit inputs, outputs, and responsibilities.
Tasks declare their dependencies explicitly, creating a directed acyclic graph (DAG) that the orchestrator resolves automatically:
export default class S3CostAttribution extends TaskDefinition {
dependencies = [
{
taskId: 'aws/data/aws-cost-by-bucket',
alias: 'bucketCosts',
required: true,
},
{
taskId: 'storage/storage-app-mapping',
alias: 'appMapping',
required: true,
}
];
async execute(context: TaskContext) {
// Dependencies completed before this task even starts executing
const bucketCosts = dependencies.bucketCosts;
const appMapping = dependencies.appMapping;
// Attribute costs to components using cached dependency results
}
}
Here's what a real task dependency graph looks like. Notice how tasks fan out and converge—multiple paths execute in parallel, while shared dependencies (like code/clone-repos-full) are executed once and reused by multiple downstream tasks. Each node shows execution time and cost.
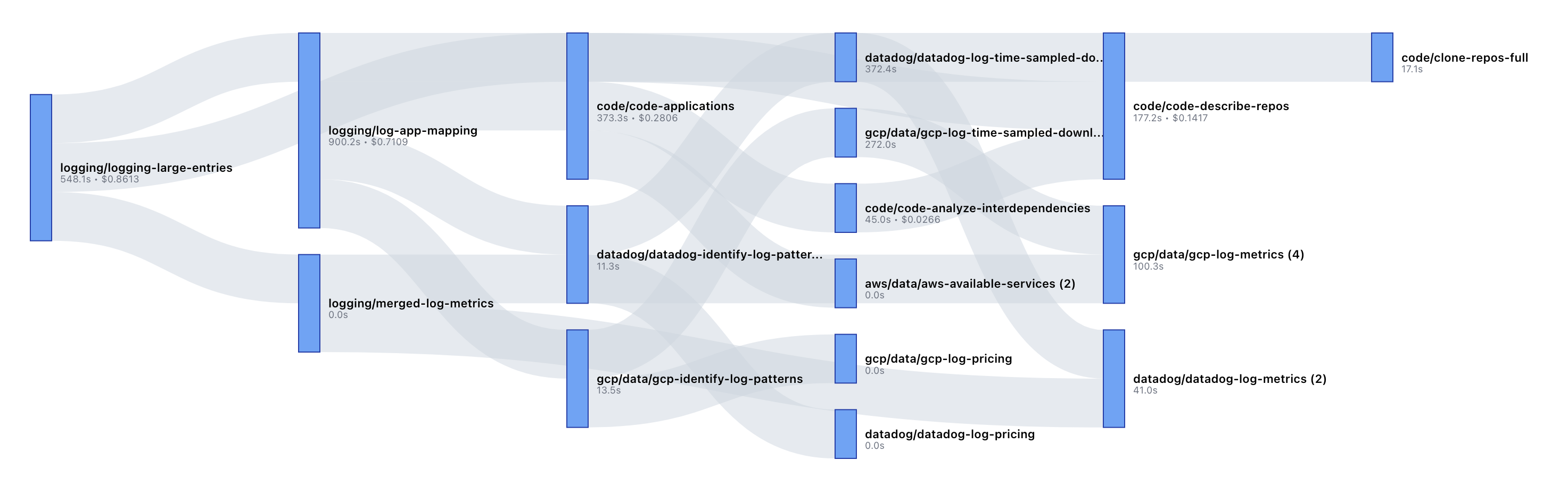
Under the hood, TaskOrchestrator uses a multi-stage queue system: Dependency Discovery → Waiting for Dependencies → Ready to Execute. Tasks flow through these stages automatically, with dependencies executed in parallel where possible.
This decomposition provides repeatable, auditable workflows with deterministic execution paths.
Hybrid Execution: Deterministic and AI-Driven Tasks
Task decomposition alone isn't sufficient—we also need to decide when to use AI versus deterministic code. The framework supports both types as first-class citizens. Data extraction and transformation tasks (billing data, observability metrics) run as pure code, while semantic analysis tasks (code intent, optimization opportunities) leverage AI capabilities:
// Deterministic task - pure code, fast execution
export default class HelloWorld extends TaskDefinition {
async execute(context: TaskContext) {
return {
message: (await context.bash('echo "Hello, World!"')).stdout.trim(),
timestamp: Date.now()
};
}
}
// AI-powered task - Claude integration built-in
export default class FruitAnalyzer extends ClaudeTaskDefinition {
async executeTask(context: TaskContext) {
return await this.callClaude(
`Give me 2-3 interesting facts about apples. Be concise.`,
z.string()
);
}
}
The orchestrator treats both task types uniformly, enabling hybrid workflows where deterministic data processing feeds into AI analysis stages.
Caching Strategy
With tasks defined and orchestrated, the next challenge is performance. AI operations are expensive—both in time and cost. For analysis tasks with overlapping dependencies, completed task outputs are cached to avoid redundant computation. This optimization is critical for performance when analyzing complex applications that combine source code, billing data, logs, and observability metrics.
The caching strategy combines multiple mechanisms to balance freshness with efficiency:
// First run: Executes fresh, stores result
await context.queue.await('aws/data/aws-cost-by-bucket'); // ~45s, $0.23
// Second run: Instant cache hit (valid TTL)
await context.queue.await('aws/data/aws-cost-by-bucket'); // ~0.1s, $0.00
// After dependency update: Automatic re-execution (needs new information from dependency)
await context.queue.await('aws/data/aws-cost-by-bucket'); // ~45s, $0.23 (fresh)
Dependency updates trigger refreshed runs of dependent tasks. TTL expiration (configurable per task) prevents indefinite staleness. Custom rules (defined per task) enable domain-specific invalidation logic like source control hash verification.
Context Management
Beyond caching, controlling what information and capabilities each AI agent receives is critical for reliable output. TaskOrchestrator provides task-specific context through the Model Context Protocol (MCP).
Each task gets its own MCP server exposing only relevant data and methods. An S3 cost analysis task receives:
- Billing data filtered to S3 services
- Storage metrics for relevant buckets
- Methods for querying pricing information
- Schema definitions for structured output
It does not receive Kubernetes metrics, database connection strings, or other unrelated tools. This constraint serves two purposes: it reduces AI agent drift by eliminating irrelevant context, and it enforces security boundaries by limiting data access.
The MCP server also defines the expected output schema. Rather than parsing free-form text, tasks return structured data validated against Zod schemas. This enables type-safe consumption by downstream tasks and eliminates parsing ambiguity.
State Management
Tasks need to share data as analysis progresses through the workflow. The orchestrator provides two mechanisms for state management:
Dependency Resolution: Tasks declare dependencies, and the orchestrator resolves them before execution. Each task receives dependency outputs via context.dependencies:
export default class CostAnalysisTask extends TaskDefinition {
dependencies = [
{ taskId: 'aws/data/fetch-billing', alias: 'billing', required: true },
{ taskId: 'code/analyze-patterns', alias: 'patterns', required: true }
];
async execute(context: TaskContext) {
// Access resolved dependency outputs
const billingData = context.dependencies.billing.value;
const codePatterns = context.dependencies.patterns.value;
// Combine data from multiple sources
return this.attributeCosts(billingData, codePatterns);
}
}
Dynamic Task Queuing: Tasks can spawn additional tasks during execution using context.queue.await(). The parent task suspends while the child executes, freeing its concurrency slot. This prevents deadlocks and enables efficient resource utilization:
async execute(context: TaskContext) {
// Dynamically queue tasks based on runtime data
const services = await context.queue.await('aws/list-services');
// Parent suspends here, child executes
const costs = await context.queue.await('aws/analyze-costs', {
services: services.activeServices
});
return costs;
}
Lambda Tasks: Dynamic Parallel Execution
The static task graph handles most workflows, but some analysis patterns require processing runtime-determined collections. For example: analyzing costs across N microservices, where N is discovered at runtime.
Lambda tasks solve this through inline, closure-based task definitions:
export default class AnalyzeServices extends ClaudeTaskDefinition {
tools = [{ taskId: 'aws/query-costs', alias: 'cost_query' }];
volumes = {
workspace: { taskId: 'code/clone-repos' }
};
async executeTask(context: TaskContext) {
const services = await context.queue.await('aws/discover-services');
const lambdas = [];
// Create one lambda task per service (closure captures 'service')
for (const service of services.items) {
lambdas.push(context.createLambda('analyze', async (ctx, task) => {
// Lambda inherits parent's tools and volumes automatically
const analysis = await task.callClaude(
`Analyze cost optimization opportunities for ${service.name}`,
CostAnalysisSchema
);
return { service: service.name, analysis };
}));
}
// Execute all lambdas in parallel (parent suspends during execution)
const results = await context.enqueueAllAndWait(lambdas);
return {
analyses: results.filter(r => r.success).map(r => r.value),
failed: results.filter(r => !r.success).length
};
}
}
Lambda tasks are ephemeral (never cached), inherit their parent's parameters, tools, and volumes, and execute in parallel across isolated Kubernetes pods with automatic concurrency management. This pattern enables map-reduce style operations over runtime data without creating separate task definition files for each item.
All task executions—both regular and lambda—are logged with full audit trails, providing traceability from final outputs back through the execution graph to source data.
Security Model
Dynamic task execution introduces security concerns. AI agents with unrestricted capabilities could access sensitive data, modify resources, or access unauthorized workspaces. TaskOrchestrator enforces security boundaries through connector abstractions and workspace isolation.
Tasks do not receive credentials directly. Instead, they access external systems through connectors:
async execute(context: TaskContext) {
// Task creates connector (credentials retrieved internally)
const aws = await AwsConnector.create(context);
// Task calls typed methods, never handles raw credentials
const costs = await aws.getCostAndUsage({
startDate,
endDate,
metrics: ['UnblendedCost']
});
return costs;
}
The connector pattern enforces several security constraints:
- Credential isolation: Credentials stored centrally, retrieved by connectors only
- Project scoping: All credential access requires
projectId, enabling workspace isolation within customer accounts - Typed interfaces: Tasks call methods like
getCostAndUsage(), not raw API calls - Deterministic capability control: Connectors are deterministic code that expose only the specific data and operations required, not general-purpose API access
External System Integration and Containerization
Security and performance are addressed, but tasks still need access to external systems and isolated execution environments. The orchestrator integrates with external systems including source control, cloud provider APIs, and observability platforms. Rather than providing raw API access, tasks receive curated tool sets specific to their requirements.
When tasks need isolated execution environments, containerization is automatic:
export default class LoggingDebugTrace extends ContainerizedTaskDefinition {
// Inherit cloned repository from dependency
volumes = {
workspace: {
taskId: 'code/clone-repos-full',
readOnly: false
}
};
async execute(context: TaskContext) {
// Runs in isolated Kubernetes pod with repo mounted at /workspace
const grepResult = await context.bash(
'grep -r "console.log\\|logger.debug" /workspace'
);
// Analyze patterns, generate report
return { debugStatements: parseGrepOutput(grepResult.stdout) };
}
}
This creates a Kubernetes pod with copy-on-write volume cloning. Downstream tasks can inherit volumes, enabling layered execution without data duplication. The orchestrator manages pod lifecycle, volume cleanup, and result caching.
Domain-specific tools for cost analysis include log pattern analyzers, prompt compression utilities, and cost attribution algorithms. These tools are loaded into task contexts only when required by the task definition.
End-to-End Execution
The previous sections described individual subsystems. This section shows how they work together when TaskOrchestrator executes a complex cost optimization scan.
When a scan initiates, the orchestrator builds a dependency graph and identifies parallel execution opportunities—billing data, repository clone, and metrics collection all start simultaneously. Tasks flow through the multi-stage queue with cache checks at each step. Yesterday's billing data? Cached. Code analysis after this morning's commit? Re-executed due to hash mismatch. Deterministic tasks access AWS through connectors that handle credentials internally. Containerized tasks run static analysis in isolated pods. AI tasks receive MCP servers exposing only relevant context—S3 analysis sees S3 code and costs, not the entire codebase. When a task discovers 50 microservices at runtime, it spawns lambda tasks to analyze each in parallel.
State accumulates through dependencies: early tasks establish baseline spend ($47K monthly), middle tasks attribute costs (API Gateway: $12K, 80% from /webhook), and final tasks produce structured Frugal Fixes with remediation guidance. All outputs validate against Zod schemas for type-safe consumption. Cached results persist across runs—subsequent scans can reuse 70% or more of task outputs, re-executing only what changed.
Implementation View
The internal web interface provides real-time visibility into task execution. The interface displays the dependency graph, cache hit/miss status, and execution state for all tasks. Cached results appear immediately, while fresh executions show progress through the queue stages.
This view is used daily for workflow monitoring, debugging, and performance analysis. All task executions, cached results, and dependency relationships are directly observable.
Design Rationale
Existing workflow frameworks (LangGraph, Temporal, Airflow) solve related problems, but TaskOrchestrator addresses a specific combination of requirements: orchestrating multiple AI agents in parallel with intelligent caching, controlling agent inputs and outputs through MCP, and Kubernetes-native containerization for cost attribution workloads. Each task exposes its cached results as MCP tools, creating a growing library of capabilities that agents can invoke. This tight integration between orchestration and AI agent execution is central to how Frugal works.
The build-vs-adopt calculus has shifted. With AI assistance, building a tailor-made system now takes similar effort to adapting an existing framework—when the fit matters this much, building your own isn't the heavyweight choice it once was.
Conclusion
The gap between AI demos and production systems isn't about model capabilities—it's about infrastructure. TaskOrchestrator provides the orchestration layer that makes AI agents reliable enough to trust with real workloads: intelligent caching reduces costs and latency, security boundaries prevent unauthorized access, and structured execution provides the audit trails required for production deployments.
Postscript
Thanks to Hai Nghiem and AGI Ventures Canada for inviting us to talk about this! https://youtu.be/JdF-pWhzECk
Ready to try Frugal Code? Request Early Access



