

Cost Engineering
It’s a tempting prompt isn’t it? Just ask Claude Code, Codex or Cursor to go and figure out how to modify your application to cut your spending on a managed service you are using.
Unfortunately, you are not setting up for success. The AI will dutifully go look at the code, it might even reach out to look at the Google Cloud Storage or S3 pricing model, and it will surely provide a set of suggestions. For a system I am currently working with, the AI initially suggested:
Purge obsolete data
Minimize downloads
Employ lifecycle rules
Regularly prune test buckets
The problem is all of those suggestions are at best ineffective and in some cases would actually increase costs for this particular application’s usage pattern of cloud storage. On top of that, changes can add complexity to your codebase, can introduce security or availability risk – so you only want to implement optimizations that will actually make a difference on your bill. The problem of course is that looking at the code, even if you know everything there is to know on the internet, is still not enough information for an AI (or a human developer) to make good choices on how to cost-optimize.
So, look at the bill! (obvs)
The bill will show you a detailed breakdown of the costs involved, which will give you hints about where you should be looking to optimize.
For instance suppose it looks something like this:

Now we are getting somewhere. 80% of the cost is coming from operations, so maybe focus there and don’t worry much about purging obsolete data, pruning and other optimizations that target the storage costs.
The billing data will actually take us a bit further in our journey to break down the operations costs. For instance in GCP, I can see the main items contributing the costs above are:

This allows us to further target our focus to any application code that is working with objects in a bucket using Coldline storage.
But suppose there are a few different places in the application that are using Coldline Cloud Storage? Which one is responsible for what portion of the bill? We need more information!
Next stop: check the metrics
Metrics reveal the next level of detail about application behaviour at run time.
For instance in GCS we might look at storage.googleapis.com/api/request_count to isolate the Multi-Region Coldline Class A Operations usage and attribute it by operation type, bucket, and application tags.
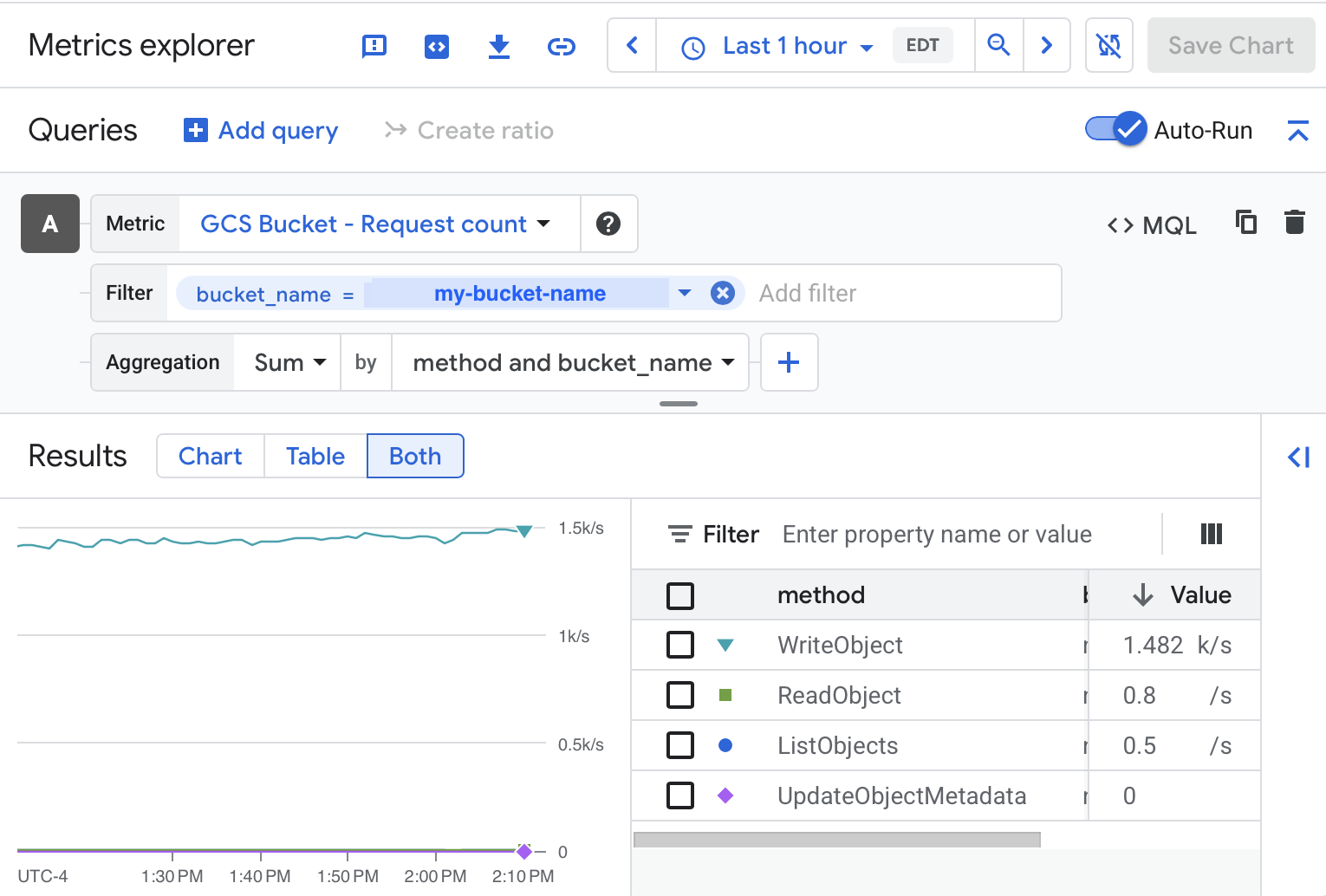
With metrics we are able to see that it's the WriteObject operations that are a problem, and narrow it to a particular bucket and application tag.
This is often enough to lead you to the code that is responsible for the bulk of the costs.
Bill >> Price List * Metrics
Good, you started with the bill! You might be tempted (as I have been) to instead start with a public price list and metrics. Companies can have negotiated discounts on certain operations, and if you are expecting to calculate costs by multiplying observed metric values by a price list that isn’t the company’s negotiated version of the price list, you are going to end up with calculated costs that are incorrect. That could lead to bad assumptions about what needs to be optimized. Stick with the bill if you can!
Finally the optimization
Now you see it. The offending block of code. That sucker is breaking the bank. Once you know, the fix is often easy enough. Introduce an in-memory cache. Batch it up. Drop the duplicates. It's been done before. Or maybe it’s adhering closer to cost-saving guidance specific to the service: choose a different storage class, make sure your prompt works with prompt caching, fix a metrics cardinality explosion. It will depend, but it's usually not complicated. Make the changes and celebrate the savings!
In closing
Achieving cost savings in your usage of managed services is going to require changes in your application code, in the end. But the moral of the story is code is kind of the wrong place to start. No matter whether you are a human engineer or an AI, the smart move is to start with the bill, understand in detail which components of the overall cost matter, move to metrics and other sources of runtime data to understand what is responsible for driving those components of cost at the detail level, and finally move into the code to find exactly the code that is driving that cost. Mix in knowledge of how to optimize the code for that situation and apply it. It's an old recipe for success, but worth a revisit as we move into the era where we are all running enthusiastic AI agents eager to take on any challenge we set for them, even the impossible tasks.
Somebody ought to automate this
At Frugal we want to make every cloud application cost-efficient.
We’re currently working with early design partners. If you want to be part of the next wave of intelligent cost engineering, join our waitlist or reach out—we’d love to hear from you.



